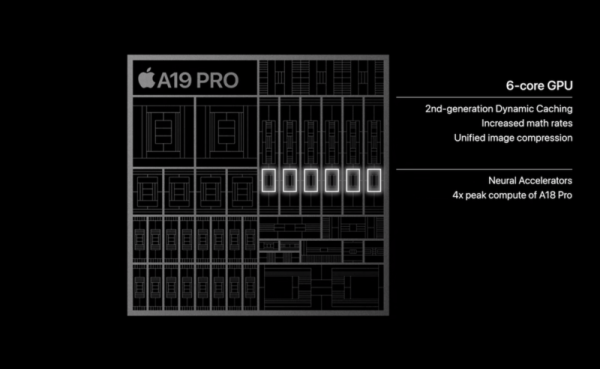
At the iPhone 17 Pro product release conference, in addition to the bright and bright new devices, a seemingly inconspicuous technical upgrade from the A19 processor architecture has attracted popularity in the AI industry. For the first time, App...
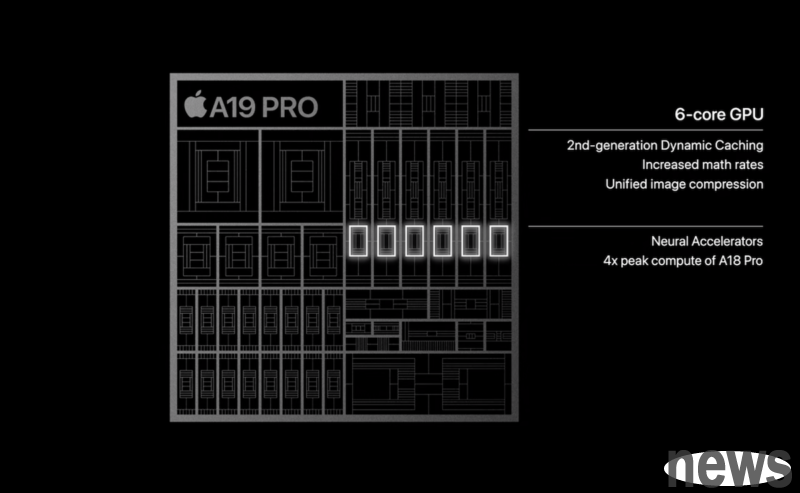
At the iPhone 17 Pro product release conference, in addition to the bright and bright new devices, a seemingly inconspicuous technical upgrade from the A19 processor architecture has attracted popularity in the AI industry. For the first time, Apple has added Matrix Multiplication Acceleration Units to its GPU, which is considered a major breakthrough for the existing AI computing power bottle, and it also indicates that Apple will face NVIDIA's dominant position in the AI field.
For a long time, one of the biggest differences between Apple's self-developed GPU and NVIDIA display cards is the lack of hardware acceleration cores designed for volume computing like NVIDIA Tensor Core. This is also the key to NVIDIA's ability to be far ahead in deep learning and large language model (LLM) computing. The latest Tensor Core not only has amazing computing speed, but also natively supports a variety of floating point accuracy (such as FP64, TF32, BF16, FP16, etc.), which can perfectly cooperate with various large-scale model training and recommendation engines.
Although Apple's GPU upgrade this time includes matrix multiplication acceleration units, this is not the same as NVIDIA's Tensor Core. Tensor Core is a more complex and comprehensive computing core. It not only performs matrix multiplication, but also provides in-depth optimization of multiple low-precision floating point computing (such as FP8 and FP6). These are keys to modern big model training and recommendations. In other words, although Apple's GPU has a shortcoming of matrix computing, its native support accuracy and computing efficiency still need to be followed by subsequent technical development.
Matrix multiplication: the core of AI computingIn the world of deep learning, whether it is training or recommendation, the most core and most complex operation is Matrix Multiplication. You can imagine a neural network as a series of complex mathematical operations, in which the connection power between each neural element can be expressed as a huge matrix. When input data (such as a picture, a piece of text) enters this network, it performs a series of multiplication calculations with these power matrixes to produce the final output.
This is why the calculation speed of "matrix multiplication" directly determines the speed of AI model training and recommendations. A good AI chip depends largely on its ability to handle these giant matrix multiplications.
Hold the GPU core computing powerIn the past, Apple has vigorously promoted its own "Neural Network Engine (ANE)" to try to handle AI tasks through dedicated hardware. However, the actual application is not as expected.
First, ANE's usage experience is extremely unfriendly, and developers must convert the model into a specific format before it can run, and the process is complicated. Secondly, and most importantly, the effectiveness of ANE has been far behind in the era. Since Apple did not initially expect the rapid rise of large language models (LLMs) based on the Transformer architecture, this model has a high demand for memory bandwidth, while ANE has a mediocre performance. According to actual results, ANE's maximum bandwidth is only about 120GB/s, not even as good as the NVIDIA GTX 1060 display card launched in 2016. This results in real applications where few developers choose to use ANE to run large models.
(Source: GitHub)
Compared with that, Apple's GPU performance is impressive. Taking the M2 Max as an example, the frequency width of its LPDDR5x unified memory can reach almost 80% of theoretical performance. This makes the industry look forward to the next generation of products. If the future M5 Max can be equipped with LPDDR6 with higher bandwidth, its memory bandwidth is expected to reach 900GB/s, which will be enough to be on par with mainstream consumer display cards.
M4 road, M5 is on the market, can PC computing power war be on the market?Apple is not a hole. On the M4 chip, Apple has started testing the water temperature, directly providing a configuration of a unified memory of up to 512GB, which shows that Apple has long recognized the large-scale demand for memory capacity of the large model.
Next year, with the full development of M5 series chips on products such as MacBook Pro, Mac Mini and Mac Studio, the new GPU that uses the matrix multiplication acceleration unit will definitely greatly improve the power of Apple devices in AI computing. This change not only makes Apple dispel the ANE of the past "chicken ribs", but is more likely to change the competition pattern of consumer-level AI devices.
Faced with Apple's strong attack, the pressure of chips such as NVIDIA, AMD and Intel can be imagined. It can be predicted that next year it will become the "ultimate battle" of AI computing power competition in the personal computer (PC) market. Can Apple use its hardware integration advantages and large ecosystem to shake NVIDIA's dominant position in the AI field? The future development of this technology war is worth waiting for us.
Apple GPU Matrix Multiplication Acceleration Units: A Technical Breakthrough Reshaping AI Computing Apple adds matmul acceleration to A19 Pro GPU